免费五行缺失查询表,新生儿五行缺失查询表
最后更新 :2021.11.25 03:11
免费五行缺失查询表
前言
本文具体探讨 MySQL 数据实时同步到 Elasticsearch (以下简称 ES ) 技术方案和思考,同时使用一定篇幅介绍一些前置知识,从理论到实践,让读者更好的理解这块内容和相关问题。包括:
为什么我们要将数据从 MySQL 实时同步到 ES ,本质是什么?
为什么是 ES,而不是其他 OLAP 引擎?
MySQL 到 ES 数据实时同步方案中有哪些细节需要注意?
MySQL 到 ES 数据实时同步方案可以有哪些选择,优缺点是什么?
相信看完本文,你会对 MySQL 数据实时同步到 ES 有更多的了解。
数据库去规范化
Database normalization is the process of structuring a database, usually a relational database, in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by Edgar F. Codd as part of his relational model.
数据库规范化是指关系型数据库中通过一系列数据库范式来减少数据冗余、增强数据一致性的策略。例如我们平时使用的关系型数据库的关系模型可以认为是 Database Normalization 的一种实现方式,这些关系型数据库基本都至少遵循了数据库第三范式,可以称之为 Normalized Database。 数据库范式的内容,本文不再展开。
Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data. It is often motivated by performance or scalability in relational database software needing to carry out very large numbers of read operations. Denormalization differs from the unnormalized form in that denormalization benefits can only be fully realized on a data model that is otherwise normalized.
Database Normalization 在带来我们看得见的好处同时(利于事务操作性能、存储成本降低),伴随数据规模扩大、并发度提高、复杂度上升,弊端也慢慢展现,这时候 Database Denormalization 能够一定程度满足这些挑战,总体思路是通过一系列降低写入性能的操作例如更多的数据冗余、数据分组等来提升数据库读取的性能。
去规范化的时机
数据去规范化动机多样,当出现因数据复杂操作影响系统稳定性、业务响应/并发要求不满足等都是触发因素。
业务稳定性问题:面向 C 端的互联 应用特征是并发量较高,SQL 偏向点查点写,相对简单,但是沉淀下来的数据(比如订单、支付等) 需要做运营往往涉及传统企业级应用对于数据库的操作特征,大范围数据栅查、表关联、排序等实时操作,以及满足报表/BI等更加复杂的数据库需求。通过去规范化和负载分离是较合理的选择。
复杂查询性能问题:企业级应用例如ERP、CRM、BOSS或者其他一些企业运营系统,经常涉及表关联、聚合、多维删选、排序等操作,并常常带来性能问题。通过去规范化的一些方式,如下文提到的数据冗余和预计算方式,显著改善性能。
去规范化的几种实现方式
假设有如下三张表,学生、班级和教师。需求是:已知学生的学号,需要查询当前学生的班主任是名字。
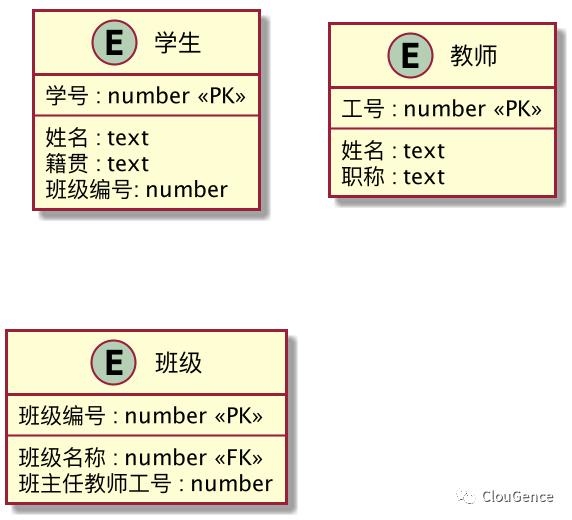
使用规范化数据查询,是一个 3 表联查操作,而在数据库中,大体分三步:
通过学生学号获取学生信息,得到班级编号
通过班级编号获取班级信息,得到班主任工号
通过班主任工号得到教师信息,得到班主任的名字
如果在数据量较大,有一定并发要求,并且涉及更多表关联时候,这种计算就不能满足需求,这个时候去规范化的优化方式就登场了。
列级处理——主查询表冗余字段
通过在主表冗余计算好的数据,可避免频繁重复计算数据。如下场景适合在主数据表内冗余数据:
应用系统需要经常获取计算好的数据
冗余的原始数据不经常变化
在学生表冗余班主任的名字信息,表的设计变为如下:

这时候查询就只有一步了:
根据序号获取学生信息,同时也得到了其班主任名字
优点:较为简单易懂,容易实现。
缺点:侵入业务逻辑,拖慢业务代码性能的同时,长期迭代所产生的变化可能会有稳定性风险。
表级处理——宽表预构建/Cube预构建
表级处理主要操作就是构建宽表,或者构建数据立方体(Data Cube)。构建好的宽表 了用户查询时需要的所有维度、度量信息。以上面学生查找班主任的问题为例,构建的宽表结构如下。

表级处理常见实现方式包括 应用多写、数据库自身实现的物化视图、数据迁移同步。
应用多写
在主数据相同数据库内创建宽表,应用写入数据的时候同时也向宽表写入数据(事务保证一致性),复杂查询即可从该表进行。
优点:实现简单、低成本
缺点:对主数据库造成更大的读写压力,外加业务改造成本。
RDBMS 物化视图
Oracle、SqlServer 等数据库物化视图方案,通过数据冗余与预计算减少 join、聚合,从而提升查询性能。例如,在 Oracle 上完成学生查找班主任这个查询,可以构建一张“学生管理表”的物化视图,查询请求直接请求物化视图即可得到查询结果,避免 join ,显著改善该 SQL 执行效率。
优点:数据库引擎自身支持,使用成本较低
缺点:RDBMS 实现的方式有自己的局限性,比如生成物化视图的数据需要做一些业务紧相关变换就无法满足,或者某些数据库并没有完整实现该能力(物化视图在 2000 年左右是数据库学术圈研究的重点)。
数据迁移同步
借助数据同步工具,准实时将主数据表数据组织变换(包括按照业务逻辑变换)形成普通表或大宽表,写入 存储引擎(如 OLAP 存储引擎或者搜索系统)。复杂查询直接在预构建好的表上或者 cube 上执行,从而达到良好的性能。数据迁移工具的选择较多,总体上按照其侧重点,可以分为如下几类:
大数据类:为大数据产品流入数据提供服务,因为大数据产品本身特点,侧重批量定时的迁移,实时同步一般需要用特别的,往往和业务特征紧耦合。常见的数据迁移同步工具有 sqoop、datax 等
流计算类:为自身流计算框架生态服务,侧重计算,迁移同步更多是类似数据连接器的角色,代表的产品如 Flink
消息类:为自身消息产品生态服务,如丰富的 kafka connector、debezium 等
数据库类:数据库厂家一般都会提供原厂工具,典型如 Oracle 的 GoldenGate
云厂商类:云厂商提供的数据迁移同步工具,主要侧重自身云上数据库生态产品之间的互融互通和将线下自建数据库的数据上云,例如阿里云 DTS, 腾讯云 DTS , AWS 的 DMS 等
专业数据迁移同步工具: 包括部分开源产品或 独立公司提供的数据迁移同步工具,例如 c、streamsets、maxwell、cloudc、striim、fivetran ,以及老牌数据集成厂商 Informatica 、Qlik 等所提供的产品
优点:
主库更稳定:异步化解耦业务系统事务查询和复杂查询,避免复杂查询对主数据库产生影响
易运维、链路稳定:数据迁移同步链路有标准化产品支撑,和主业务系统、主库读写解耦。整体架构上职责清晰,易于维护和问题追踪
缺点: 需要对纷繁多样的数据迁移同步工具、承载复杂查询数据库产品选型,对技术同学能力有一定要求
MySQL 到 ES 数据实时同步技术架构
我们已经讨论了数据去规范化的几种实现方式。MySQL 到 ES 数据同步本质上是数据去规范化的一种。本节我们展开讨论“MySQL 到 ES 数据迁移同步”的技术解决方案,通过比较他们的优缺点和应用场景给读者提供一些思路。
为什么是 MySQL
MySQL 在关系型数据库历史上并没有特别优势的位置,Oracle/DB2/PostgreSQL(Ingres) 三老比 MySQL 开发早了 20 来年, 但是乘着 2000 年的互联 东风, LAMP 架构得到迅速的使用,特别在中国,大部分新兴企业的 IT 系统主数据沉淀于 MySQL 中。
高并发能力:MySQL 内核特征特别适合高并发简单 SQL 操作 ,链接轻量化(线程模式),优化器、执行器、事务引擎相对简单粗暴,存储引擎做得比较细致
稳定性好:主数据库更大的要求就是稳定、不丢数据,MySQL 内核特征反倒让其特点鲜明,从而达到很好的稳定性,主备系统也很早就 ready ,应对崩溃情况下的快速切换,innodb 存储引擎也保障了 MySQL 下盘稳定
操作便捷:良好、便捷的用户体验(相比 PostgreSQL) , 让应用开发者非常容易上手 ,学习成本较低
开源生态:MySQL 是一款开源产品,让上下游厂商围绕其构建工具相对简单,HA proxy、分库分表中间件让其实用性大大加强,同时开源的特质让其有大量的用户
为什么是 ES
ES 几个显著的特点,能够有效补足 MySQL 在企业级数据操作场景的缺陷,而这也是我们将其选择作为下游数据源重要原因
文本搜索能力:ES 是基于倒排索引实现的搜索系统,配合多样的分词器,在文本模糊匹配搜索上表现得比较好,业务场景广泛
多维栅选性能好:亿级规模数据使用宽表预构建(消除 join),配合全字段索引,使 ES 在多维删选能力上具备压倒性优势,而这个能力是诸如 CRM, BOSS, MIS 等企业运营系统核心诉求,加上文本搜索能力,独此一家
开源和商业并行:ES 开源生态非常活跃,具备大量的用户群体,同时其背后也有独立的商业公司支撑,而这让用户根据自身特点有了更加多样、渐进的选择
为什么是数据迁移同步方式
相对于数据去规范化的其他几种方案,数据迁移同步方式存在以下几个优点,也是其成为目前业界主流方式的原因
稳定性好:迁移同步对主数据库的操作主要是进行数据和日志的顺序读取,同时并发小,对主数据库稳定性影响较小(较多的下游订阅可能在 络层面存在影响,一般用消息解决)。另外日志(Binlog/WAL/Redo等)可重放特质,让下游丢数据的可能性大大减小(处理好幂等的情况下)
业务解耦:一般而言主数据库更多承载事务型操作,而下游数据系统承载运营等层面的业务, 典型如电商的买家侧和卖家侧业务
业务侵入小:数据迁移同步对业务无侵入,双端对接标准数据库(源),可以便利地找到开源、商业、云等各个方向的成熟解决方案或产品
业务适配性好:某些数据迁移同步产品能够嵌入业务逻辑,让下游获取到更加贴近业务的数据,从而让数据服务更加有效和便捷
数据迁移同步模型选择订阅消费

优点
堆积能力:由于引入了消息队列,所以整个链路是具备变更数据的堆积能力的。假设变更数据消费的比较慢,MySQL 本地较老的 binlog 文件由于磁盘空间的不足而被 时,消息队列中的数据仍然存在,数据同步仍然可以正常进行
数据分发能力:引入消息队列后可以支持多方订阅。如果下游多个应用都依赖源端的变更数据,可以订阅同一份 topic 即可
数据加工能力:由于变更数据是由下游消费者订阅,因此订阅后可以灵活的做一些数据加工。例如从外部调用微服务接口或者反查一些数据来做数据加工都是比较方便的
缺点
运维成本相对较高: 了较多的组件和应用,运维保障相对复杂。
稳定性风险较高:一环出问题会导致整个数据同步链路的稳定性受到影响。而且排查和定位问题也会比较困难。
端到端直连
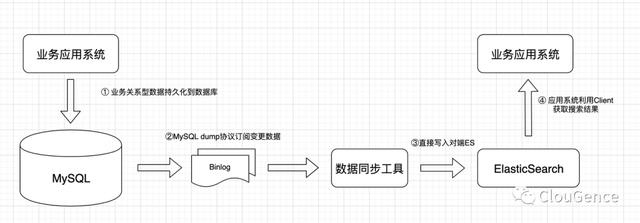
优点:
低延迟:端到端的直接同步,链路较短,延迟低
稳定性好:链路组件少,出问题概率较低,定位排查均比较容易。适合对数据精确性高的严苛场景。
功能拓展性强:对端写入消息系统,模拟订阅模式,可扩展性强
运维部署简单:链路组件少,部署运维更简单
缺点:
无
数据迁移同步模型选择总结
从笔者以往的经验来看,如果没有众多的下游数据订阅,建议采用直连模式。数据同步链路往往置于在线业务中,随着业务规模以及重要性逐渐加大,链路 稳定性 更为重要些。另外 端到端模式 只要支持对端数据源为消息中间件,可立刻实现订阅模式,数据加工能力在某些数据迁移同步产品上可通过上传业务代码运行的方式解决。
数据架构在满足业务需求的同时,简洁和清晰能够让系统更加易于维护和排查,当遇到链路每天同步几千万条上亿条数据、偶发丢几条需要排查,或同步链路卡住不同步等情况,端到端方式往往体现出相当大的优势。
MySQL 到 ES 数据实时同步核心挑战
关系型数据库中不同表之间的数据常存在关联,同步到 ES 之后,这种关联关系该如何去组织,同时又能够很好的匹配到 ES 的更佳实践 ? 本小节会展开讨论这个问题,并对常见的数据同步工具选型提供一些参考对比。
MySQL 关联表在 ES 上的设计
关系型数据库库中的表 join 关系在 ES 可以用几种数据类型来表达,包括 objected,nested,join 三种。
objected
object 类型可以存储嵌套结构.
优点:
表示主 field 和 object 内部 field 之间的一对多关系,支持 doc 的 join 查询。由于所有查询时依赖的关联数据也都在一个文档内,避免了 ES 内部的 join,查询效率较高
缺点:
一对多关系只能保留一层,多于一层的会被打平,会丢失嵌套 field 内部的关联关系。下面的例子中,之一幅图看到写入 ES 的是一条订单数据,其中 producets 这个 field 是 object 类型,其中 了多个产品的记录。
当采用 objected 字段存储 products 信息时,原本存储 如下:
“order_id” : 123,”products” : [ { “price” : 10, “sku” : “SKU_10”, }, { “price” : 20, “sku” : “SKU_20”, }]
在ES中存储的样子为:
{ “order_id”: [ 123 ], “products.price”: [ 10, 20], “products.sku”: [ SKU_10, SKU_20 ],}
可以看到在ES的存储中,producets 中每个字段的值都已经被打平处理。如果我们查询订单 ID 为 123,价格 price 为 10,SKU 为 “SKU_20” 的文档,我们同样可以搜索到结果,但这样显然就丢失了其内部之间的关系了。
nested
nested 类型可以存储嵌套结构,表示一对多关系,是 object 类型的拓展
优点:
不会出现 object 的缺点,整个嵌套关系是完整维护的,子文档内部的关联关系保存是完整的
关联数据通过实现上自然关联到主文档上,搜索时性能较好(相对于 join 类型)
缺点:
一个 nested field 只能属于一个主文档
在 nested 类型中,子文档和主文档之间是强绑定,主文档更新的时候会强制更新子文档。在写多读少的场景,性能开销较大
child 文档的查询必须通过父文档再找到子文档
子文档频繁修改的话会影响别的子文档和父文档,因为本质上在 lucence 实现上是父文档下的冗余存储
join
join 类型可以配置父子文档,通过父子文档来实现一对多的能力,一个索引只能建一个。相比 nested 类型,该类型更加灵活。父子文档之间通过 parentId 来关联,实际实现上他们就是独立的文档。因此带来的好处主要是
优点:
子文档更新不影响父文档和其他子文档
一个子文档可以单独搜索
一个文档在作为子文档时可以自己选择属于哪个父文档。通过relation可以指定不同的join列
缺点:
需要建个全局序数,用于服务于父子文档的关联关系,这个会影响搜索性能
join 和 nested 类型比较
join 适合写多读少场景,更加适合 索引性能的场景。这意味着更新的生效会更快,但是搜索时的开销也相对大些
nested 适合读多写少的场景,更加 搜索的性能
MySQL 到 ES 实时数据同步实现去规范化
在了解 ES 的一些关键类型之后,我们就可以描述通过数据同步去规范化的几种实现方式。
主表冗余数据
业务侧将一些查询时需要的关系数据提前冗余在源表的一个字段中。例如序列化成json存储在源表的一个冗余字段内,利用数据同步工具写入对端 ES 的 join/nested 类型字段。例如我们有订单表和商品表如下图所示。假设我们的搜索需求是,给定一个订单ID,同时将这个订单的订单明细以及所有 的多件商品的明细全部搜索出来。

如果采用这种列级处理模式,我们在订单表新增一个冗余列,然后将商品表的所有明细信息,按照kv组织成json写入冗余列即可,如下图所示。对端 ES 的 mapping 结构按照如式定义。数据同步工具直接将该保函关联表数据的订单表直接同步到对端 ES ,即可在 ES 上搜索符合我们需求的数据。
<img src="https://p5.toutiaoimg.com/large/pgc-image/SSND0Hi7wlQx7z" }, } } }}
优点:
处理模式能应对各种一对多的关联关系,对数据同步工具的功能要求低,配置简单,只需要支持单表同步到 ES 即可。
缺点:
索引、搜索性能非更佳:提供给 ES 的不是预构建好的宽表数据。例如例子中,订单关联的商品信息,全部存储在主表的一个object/nested/join 字段内,这种实现方式会有索引、搜索性能方面的额外开销,不是性能更佳的实现方式
业务系统侵入:业务系统写主数据的时候需要额外写入信息
主数据库表冗余过多数据:关系型数据库的表冗余了过多其他表 ,可能存在存储和性能开销
总结
不太推荐该方式
多表订阅合并预构建宽表数据
数据同步工具同时订阅搜索时依赖的所有表,先到的数据先进到 ES,没有数据过来的字段为空。以上面提到的订单和商品表的例子来说,即同时同步订单表和商品表到对端索引。对端索引的 mapping 定义如下所示, 订单和商品表的所有字段,定义的索引是一张宽表。流计算中多流汇聚配合时间窗口 join 多表的方式与该种方式有异曲同工之处。
优点:
数据同步工具配置同步任务较为简单,无业务入侵,不耦合业务系统逻辑
对数据同步工具要求低,除了同步以外,不需要其他额外的功能特性
基于预构建宽表的方式在 ES 上也有较好的索引和查询性能。
同步链路不会因为宽表某些列缺失数据阻塞整个数据链路的同步(是否有该优点取决于数据同步工具本身设计,如果引入时间窗口,则同步链路会因为等待列数据影响同步时效性)。
缺点:
基于事实表主动触发式的方式来进行宽表的构建。源端订阅的表,如果更新很少或者从来不更新产生 binlog,则对端的文档中的列值可能一直不完整,导致时效性会比较差。搜索的时候有一些列的数据会缺少
总结
适合构成宽表的事实表数据写入有事务保证一起落盘的场景,这样可以避免对端ES搜索到不完整的数据。
适合构建宽表不需要业务加工处理的场景,构建宽表只是单纯的将多张表的列拼接在一起,形成宽表。
{ “mappings”: { “_doc”: { “properties”: { “order_id”: { “type”: “long” }, “order_price”: { “type”: “long” }, “product_count”: { “type”: “long” }, “discount”: { “type”: “long” }, “product_id”: { “type”: “long” }, “product_unit_price”: { “type”: “long” }, “product_name”: { “type”: “text” }, } } }}同步过程回查预构建
数据同步工具订阅的表称为主表。数据同步过程中,反查数据库查询的表称为从表。利用数据同步工具自身的能力,在订阅主表期间,自动通过回查的方式,填补宽表中的列,形成完整的宽表行数据。对端 ES 的mapping 定义例子与“多表订阅合并预构建宽表数据”中的保持相同。
优点:
基于反查的方式构建宽表灵活性好,可以在生成宽表前基于主表的数据对从表数据做一些轻度的数据加工
一条主表的数据,通过反查生成宽表行,可以配合数据加工生成多条宽表行数据
基于反查的方式可以比较轻松的实现跨实例的 join ,从而生成宽表行(相对好实现,具体要看数据同步工具本身是否支持)
基于宽表预构建的方式在 ES 上有较好的索引、查询性能。
缺点:
反查时数据可能没有准备好,导致数据缺失(这里具体的影响取决于数据同步工具本身设计,可以引入时间窗口配合超时等待,也可以没有数据时直接同步到对端)
需要数据同步工具在数据反查、数据加工方面进行支持
总结
对于构建宽表涉及数据加工的场景,该方式比较适合。
由于该方式的回查机制、预构建前数据加工的能力支持,能力上是“多表订阅合并预构建宽表数据”这种方式的超集。如果有比较好的数据同步工具支持,这种方式是比较推荐的。
数据迁移同步工具选型
数据迁移同步工具的选择比较多样,下表仅从 MySQL 同步 ES 这个场景下,对一些笔者深度使用研究过的数据同步工具进行对比(不一定精确,如有错误请 笔者更正),用户可以根据自己的实际需要选取适合自己的产品。
特性\产品
C
DTS
CloudC
是否支持自建ES
是
否
是
ES对端版本支持丰富度
中
支持ES6和ES7
高
支持ES5,ES6和ES7
中
支持ES6和ES7
嵌套类型支持
join/nested/object
object
nested/object
join支持方式
基于join父子文档反查
无
基于宽表预构建反查
是否支持结构迁移
否
是
是
是否支持全量迁移
是
是
是
是否支持增量迁移
是
是
是
数据过滤能力
中
仅全量可添加where条件
高
全增量阶段where条件
高
全增量阶段where条件
是否支持时区转换
否
是
是
同步限流能力
无
有
有
任务编辑能力
无
有
无
数据源支持丰富度
中
高
中
架构模式
订阅消费模式
需先写入消息队列
直连模式
直连模式
监控指标丰富度
中
性能指标监控
中
性能指标监控
高
性能指标、资源指标监控
报警能力
无
针对延迟、异常的报警
针对延迟、异常的钉钉、短信、邮件报警
任务可视化创建配置管理能力
无
有
有
是否开源
是
否
否
是否免费
是
否
是
社区版、SAAS版免费
是否支持独立输出
是
否
依赖云平台整体输出
是
是否支持SAAS化使用
否
是
是
写在最后
MySQL 到 ES 数据同步构建数据检索服务给中小企业带来了稳定且实用的在线数据方案,在满足业务诉求(高并发业务与企业级应用常态化)的同时 ,易上手且具备不错的可维护性,在适当的场景下,值得尝试和实践。
最后感谢各位的阅读,内容相对浅显且直接,希望对你有所帮助和启发。在此也简单介绍下笔者自己,本人在阿里巴巴中间件和云智能团队从事过几年数据相关工作,在该领域具备一定的经验,对这个方向感兴趣的朋友可以一起探讨相关技术问题,我们专门开设了一个问答社区 askcug.com 以便大家探讨,欢迎加入探讨。
参考资料
[1]:Database normalization
[2]:Denormalization
[3] When and How You Should Denormalize a Relational Database
[4] 爱奇艺|海量数据实时分析服务技术架构演进
[5] 从 ES 到 Kylin,斗鱼客户端性能分析平台进化之旅
[6] 常见开源OLAP技术架构对比
[7] Elasticsearch:Tune for search speed
[8] Elasticsearch:Field data types
[9] Designing Data-Intensive Applications
[10] Materialized Views
[11] A Relational Model of Data for Large Shared Data Banks
参考阅读
不要以 DRY 之名,发明低代码 DSL 去残害你的同事
如何编写 C++ 20 协程(Coroutines)
领域驱动设计(DDD)在爱奇艺打赏业务的实践
Redis 日志篇:无畏宕机实现高可用的杀手锏
喜马拉雅自研 关架构演进过程
技术 及架构实践 ,欢迎通过 菜单「 我们」进行投稿。
高可用架构改变互联 的构建方式
以上就是与免费五行缺失查询表相关内容,是关于数据迁移的分享。看完新生儿五行缺失查询表后,希望这对大家有所帮助!
男朋友分手后挽回男友 男朋友很决绝的和我分手了,我该如何挽回?
男朋友很决绝的和我分手了,我该如何挽回?爱情不会是一帆风顺的,两个人在一起争吵,磨合,甜蜜会有的,但爱情总归是需要经营的,会经营的感情才会长久,那么面对男朋友提出分手,怎么做才能挽回男朋友的心呢?你是不是做了很多挽回的事...
qq说说指哪里(qq中的说说是什么)
QQ说说指哪里?解锁社交媒体的秘密通道 在数字时代的浪潮中,社交媒体成为了人们表达自我、分享生活的重要平台。作为中国最受欢迎的社交平台之一,QQ空间以其独特的魅力吸引着亿万用户。而在这个平台上,QQ说说则扮演着举足...
盐城哪里起名好(盐城哪里起名好听点)
盐城哪里起名好:探寻起名之道的文化瑰宝 盐城,这座历史悠久、文化底蕴深厚的城市,对于起名这一传统艺术有着独特的追求和热爱。在寻找盐城哪里起名好时,我们不仅要考虑传统文化的底蕴,还要结合现代社会的审美需求,以及起名...
诸暨哪里能取名(诸暨哪里取名字好)
诸暨哪里能取名?探索当地的文化与传统 诸暨,这座历史悠久、文化底蕴深厚的城市,向来重视命名的重要性。无论是为新生儿取名,还是为企业、店铺起名,人们都希望能找到一个寓意美好、吉祥如意的名字。那么,在诸暨,我们该去哪里...
杜氏怎么起名(杜氏男孩起名) 姓氏杜的名字男孩

根据“杜氏”起名:传统与现代的融合 “杜氏”作为一个古老的姓氏,在中国文化中有着深厚的...
广东省茂名市吴氏吴廷瑜支系分述

据《中国姓氏通史·吴姓》、《中国吴氏通书》等书记载:吴氏出自中华民族共同祖先——黄帝...
农村说迁坟是大忌!“切莫迁坟,十迁九败”!这是为啥?

在我国漫长的文化发展历史之中,农民占据了重要的一部分,不仅为人们提供的粮食,也提供了丰富...
桂平:消失的古城楼

桂平:寻访桂平以前的古仔(十二)——城门楼桂平:消失的古城楼...
办公室放鱼缸哪个位置好(办公室放鱼缸有什么讲究)
在现代都市生活中,鱼缸是一种富有生活情趣的物品,它不仅能够给人带来美观的视觉感受,还能带...
2023年属蛇人运势运程每月运程 2023年属蛇人的全年运势详解

以下是2023年属蛇人每月运势的简要预测: 2023年1月属蛇人运势 1月份属蛇人的运势比较平稳...
今年运势测试 测测今年运势算命

好的,请告诉我你的生肖和出生年份,我可以为你测算今年的运势。...
93年应该属什么生肖 93年属什么生肖多大了
大家好,如果您还对93年应该属什么生肖不太了解,没有关系,今天就由本站为大家分享93年应该属...
钟姓女孩起名五行缺火缺木 姓钟缺火的女孩名字大全

老铁们,大家好,相信还有很多朋友对于钟姓女孩起名五行缺火缺木和姓钟五行缺火缺水的男孩名...
五行缺木男孩起名姓司什么 五行缺木的男孩的字

大家好,五行缺木男孩起名姓司什么相信很多的网友都不是很明白,包括适合五行缺木的男孩名字...
梦见衣服穿反了是什么 梦见衣服穿反了佛滔算命
大家好,如果您还对梦见衣服穿反了是什么不太了解,没有关系,今天就由本站为大家分享梦见衣服...
梦见踩牛粪是什么意思 梦见踩牛粪了是什么意思

老铁们,大家好,相信还有很多朋友对于梦见踩牛粪是什么意思和梦见踩牛粪是什么意思呀的相关...
2022年12月20日喜神方位 五行八字喜用神查询

喜神是生辰八字当中的一个命神之一,不仅代表着我们的命运,也代表着一天的运势情况。也就是...
算命的看手相算出姓名 看手相,算命

大家好,今天来为大家分享算命的看手相算出姓名的一些知识点,和算命 手相的问题解析,大家要...
怎么会增加自己的财运 怎么能增加自己的财运

大家好,今天来为大家解答怎么会增加自己的财运这个问题的一些问题点,包括有没有增加财运的...
事业运不好生肖 今年运势不好的生肖有

大家好,事业运不好生肖相信很多的网友都不是很明白,包括事业财运大好的生肖也是一样,不过没...
怎么在群里撒狗粮秀恩爱 怎么聊天撒狗粮

对于现在的很多年轻人来说在交友方面可能比较的随意和撒性,大家在面对自己喜欢的朋友或者...
世界上最有钱的人是谁,现在谁是世界上最有钱的人?

提起世界上最有钱的人是谁,大家都知道,有人问现在谁是世界上最有钱的人?,另外,还有人想问世...
抖音名字怎么写吸引人 抖音什么网名吸引粉丝

抖音是近几年十分热火的app,无论小孩、大人都在刷着抖音,因此,抖音也成为了现在应用程序里...
生辰八字称骨算命查询免费 生辰八字骨骼称重

大家知道生辰八字骨骼称重吗?这个东西和生辰八字的关系大吗,大家对于自己的运势都是十分上...
98年属虎何时遇到正缘 98年属虎的桃花运

很多人一生中可能只会谈一段恋爱,一谈就是一生。但是也有的人一生可能会遇见很多人,受过很...
2022年属龙人的全年运势男,2022 年属龙的全年运势

2022年属龙人的全年运势男 生肖龙在12属相中,可谓风光无限,他们不断是权益、不祥、聪...
2022属马的,2022年属马人的全年运势男性

2022属马的 2022属马的今年运势怎么样 2022年对生肖属马的人来说,是一个喜事相逢年份,喜上...
88年属龙男的姻缘何时出现,1988年属龙男一生有几次婚姻

88年属龙男的姻缘何时出现自古我们都说“千里姻缘一线牵”,可见夫妻姻缘早已被“月老”用...
76年属龙人三大坎,1976年属龙是什么命

76年属龙人三大坎 龙人对生活充满热情和奉献他们奋斗了大半辈子为了得到自己想要的生活,...
1983年属猪人的运势,1983年属猪的一生财运

1983年属猪人的运势1983年属猪的人2022 年整体运势83年出生的属猪朋友,今年你们进入2022 ...
95年属猪女2022年感情运势,1995属猪女财运贵人

95年属猪女2022年感情运势 生肖猪女命今年本命年大凶,太岁当头坐、无灾也有祸,所有生肖中...
虎年牛的运势2022运势,虎年属牛的运势怎么样

虎年牛的运势2022运势 属牛处女座具有老黄牛踏实肯干,兢兢业业的品德,也有处女座追求...
属蛇的与什么属相犯冲,属蛇女配什么属相男更佳

属蛇的与什么属相犯冲 总结我们都知道,生活中很多人搭配在一起的时候是很般配的,很多人一...
属兔的2022年多少岁了,63年属兔人2022 年运程

属兔的2022年多少岁了 属兔2022年多大 出生在1939年的属兔人,2022年的实际年龄83岁,虚岁的...
1990男马1992女猴相配,1990马和1992猴生宝宝属相

1990男马1992女猴相配 娱乐圈里处处都是好看的皮囊,身处其中的艺人,稍微把持不住,就会乱花...
72年的跟什么属相配夫妻更好,属鼠的和什么属相最配

72年的跟什么属相配夫妻更好从恋爱心理学来说,我国的婚姻讲究男女属相搭配,很多人认为一定...
1988年属龙人的财运方位,1988年属龙人33岁后命运

1988年属龙人的财运方位 为大家分析生肖运势,喜欢的请 ↑ 1988年属龙人2022 年生肖运势:悲...
两个鼠在一起合财么,两个都属鼠的结婚好吗

两个鼠在一起合财么 属鼠的人和什么属相做生意合财 三合三合是种明合,光明正大地合,就 生...
为什么说十鼠九苦72,72属鼠三年大运

为什么说十鼠九苦72 属鼠的人,是位自尊自爱的人,也是位机智的人,而且还很细心,不过,属鼠的人...
2022年是虎年6月,2022年二牛耕田八龙治水

2022年是虎年6月 国务院办公厅近日发布通知,2022年法定节日安排如下,总共有31天,具体如下:...
- 数据加载中,请稍后...